PROJECT: Calgo
Overview
This portfolio page highlights some of my contributions to Calgo - a Software Engineering project developed in my second year of undergraduate studies in the National University of Singapore.
About the Team
We are 5 Year 2 Computer Science undergraduates reading CS2103T: Software Engineering.
About the Project
Calgo is an all-in-one personal meal tracking assistant which seeks to encourage a healthy lifestyle among its users. It allows users to not only have a convenient nutritional record of all their favourite food entries, but also track, monitor, and plan their food consumption. Moreover, the team has come up with a plethora of user-centric features to make Calgo well-suited to provide users with both convenience and utility.
My team was tasked with morphing an existing Address Book Level 3 (AB3) project into a new product via Brownfield software development. We were therefore required to use the existing AB3 project as Calgo’s project foundation, to create a desktop application supporting the Command Line Interface. This was to target users who prefer typing but also enjoy the benefits of a Graphical User Interface. With all of us being food lovers and realising a greater societal need for healthy eating, Calgo was born.
Summary of contributions
Enhancements
-
Major enhancement: I implemented categorical search via the
findcommand.-
What it does: This allows users to search for
Foodentries by narrowing down on a specificFood-related attribute of eitherName,Calorie,Protein,Carbohydrate,Fat, orTag. -
Justification: Users now have an option to perform refined searches, preventing the need to tediously scroll through the
Food Record. -
Highlights: This enhancement requires in-depth understanding of the application’s architecture. A new parser for the
findcommand was created to detect different prefixes entered by the user, as with supporting classes to facilitate background workings.
-
-
Major enhancement: I implemented the
exportcommand.-
What it does: This allows users to export their current
Foodentries to a portable, neatly formatted editable .txt file. They can now also add their own notes and share their entries. -
Justification: This improves user experience as they can now obtain a copy of their
Foodentries for multiple purposes like printing onto paper. -
Highlights: This enhancement requires comprehensive understanding of how commands are processed. A new class for the command, as well as supporting classes (such as for table formatting) were created. Moreover, as the
reportcommand is similar, we applied good OOP practices for better code quality and reuse.
-
-
Minor enhancement: I implemented substring search via the
findcommand.-
What it does: This allows users to search for
Foodentries by typing incomplete keywords for searching using theNameorTagprefixes. Results are entries containing these substrings. -
Justification: Users no longer have to type the full keyword. Those who are lazy, or happen to enter incomplete keywords can still have their results shown.
-
Highlights: This enhancement relies on
Predicates, as with categorical search above.
-
-
Minor enhancement: I implemented the lexicographical ordering of
Foodobjects.-
What it does: This makes the
Food Recordshow all entries in lexicographical order. -
Justification: It is frustrating to scroll through messy entries.
-
Highlights: We perform sorting only when Calgo starts up or when new entries are added for efficiency.
-
-
Code contributed: You can view my contributions to Calgo here.
-
Other contributions:
-
Documentation:
-
Wrote sections for
find,list,exportof the User Guide: #117, #141, #159, #160, #206, #217, #223, #226, #268, #272, #278, #287 -
Wrote sections for Storage Component, Searching, Lexicographical Ordering, and Exporting, of the Developer Guide: #123, #124, #141, #245, #259, #272, #275, #278, #287
-
Miscellaneous contributions: #65, #67, #68, #89, #116, #121, #165
-
-
Project and team management & contributions:
-
Update team pages/documentation: #40, #42, #52, #65, #67, #89, #117, #121, #123, #124, #141, #159, #160, #206, #223
-
Team lead: facilitated meetings and discussions, standardisation, providing technical help. Also reviewed some PRs: 1, 2
-
Product ideation, user testing, facilitating issue tracker and milestone management, curating some JUnit tests (e.g. for
findcommand).
-
Beyond the team:
-
Contributions to the User Guide
Given below are sections I contributed to the User Guide. They showcase my ability to write documentation targeting end-users. Please note that some hyperlinks may not work as the guide is not part of this portfolio. |
find : Finding a Food entry by nutritional value or keyword(s)
(by Eugene)
When you have many entries in the Food Record, it may be rather difficult to search for a particular one.
This is where the find command comes in nicely.
The find command shows all Food entries that have a nutritional value matching what you specify. This can be the
number of calories, or the number of grams of protein, carbohydrate or fat.
Alternatively, you can choose to search for a keyword which appears in any part of the name or in one of the tags
associated with a particular Food entry.
Here are some key pointers:
If you’re a fast typist, fear not! We understand the possibility that typing errors can be made quite often, so any
additional input for the find command without a preceding Prefix (e.g. n/, p/) will be ignored.
|
The Food Record displays the relevant entries of each find command. We can reset the Food Record to show all
entries once again using the list command.
|
Format: find [n/NAME] [cal/CALORIES] [p/PROTEINS] [c/CARBOHYDRATES] [f/FATS] [t/TAG]
(Reminder: choose only 1 parameter)
Examples:
Example 1: Say you want to use Calgo to search for a Food entry with 150 calories because you are
looking for a light snack. Here is how you can do it:
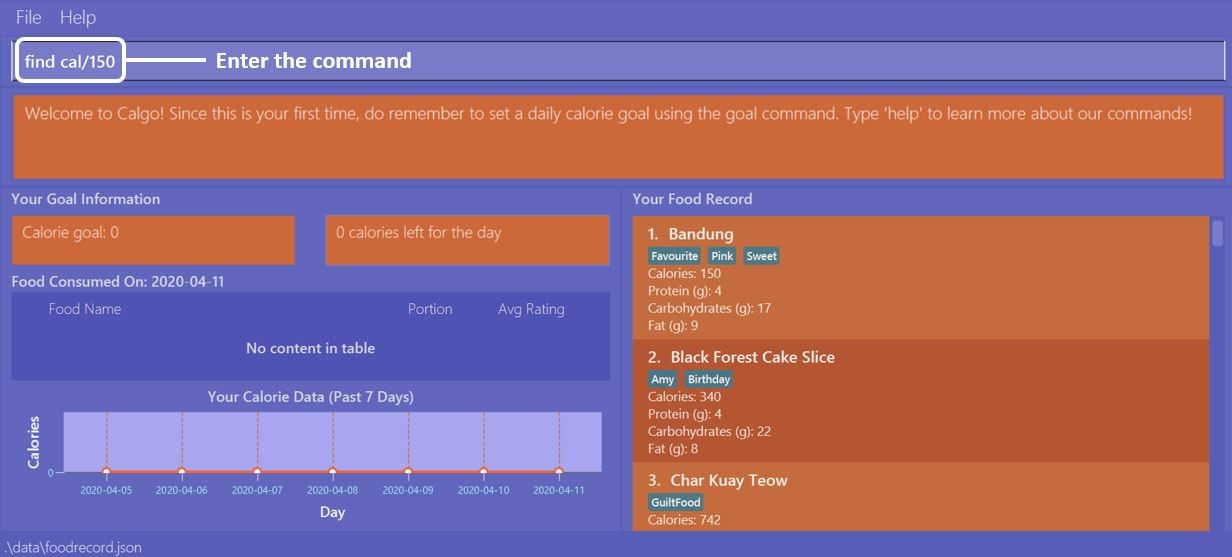
You should type find cal/150, then press enter.
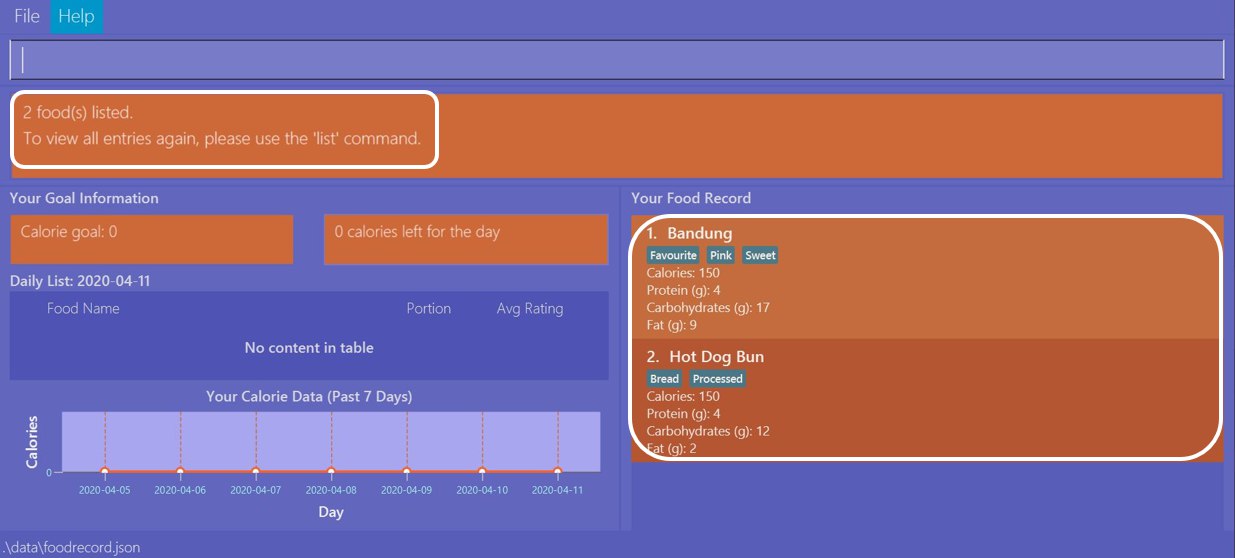
Once the command has been entered, the Result Display shows the results of your command and the Food Record
displays the relevant entries with 150 calories.
Example 2: Say you wish to find entries which contain the keyword Cheese in their name, but your hand slipped and
the keyboard only typed Chees. This is what happens:
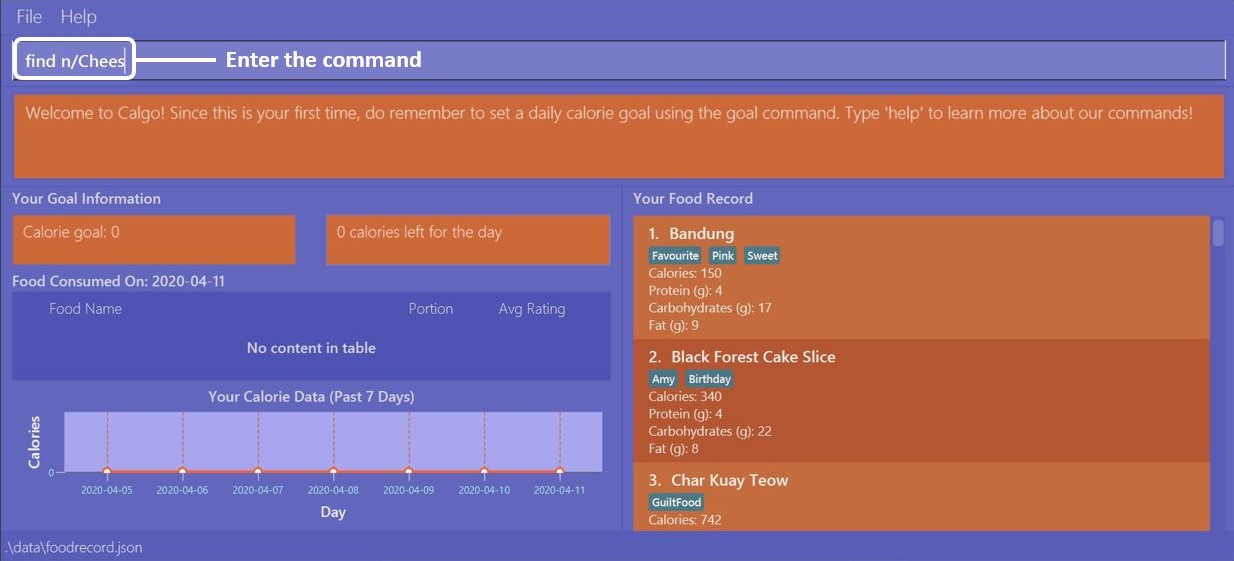
You are likely to enter find n/Chees as the command input.
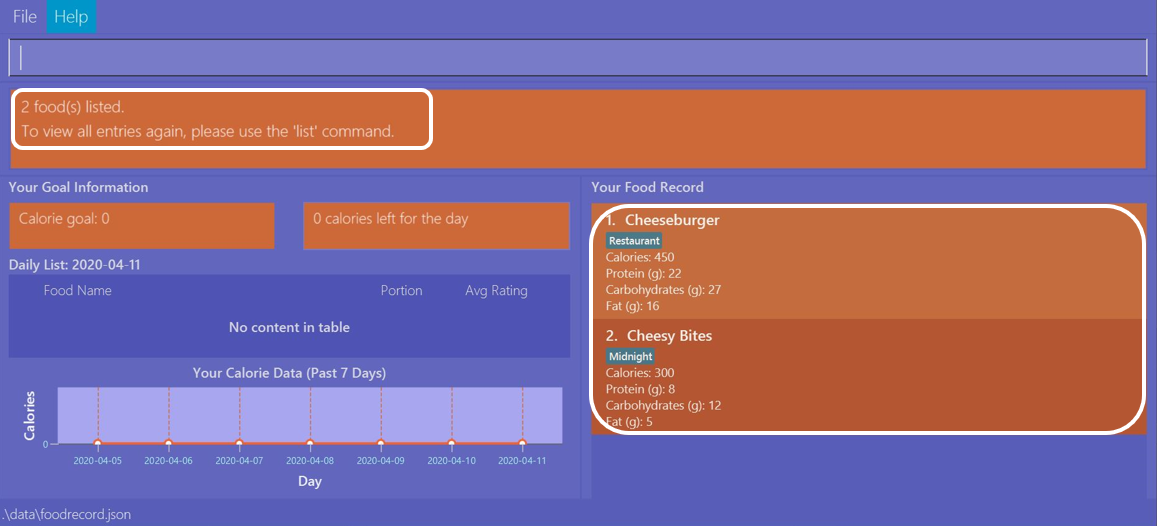
Once the command has been entered, the Result Display shows the results of your command and the Food Record shows
the relevant entries which contain Chees in their name. This is not too bad, as you still obtain entries that will
be largely relevant to Cheese. This shows that the find command can search for Food entries
with incomplete keywords.
Example 3: Say you are lazy but wish to find entries containing the keyword sweet in their tag. Here is how you can do it:
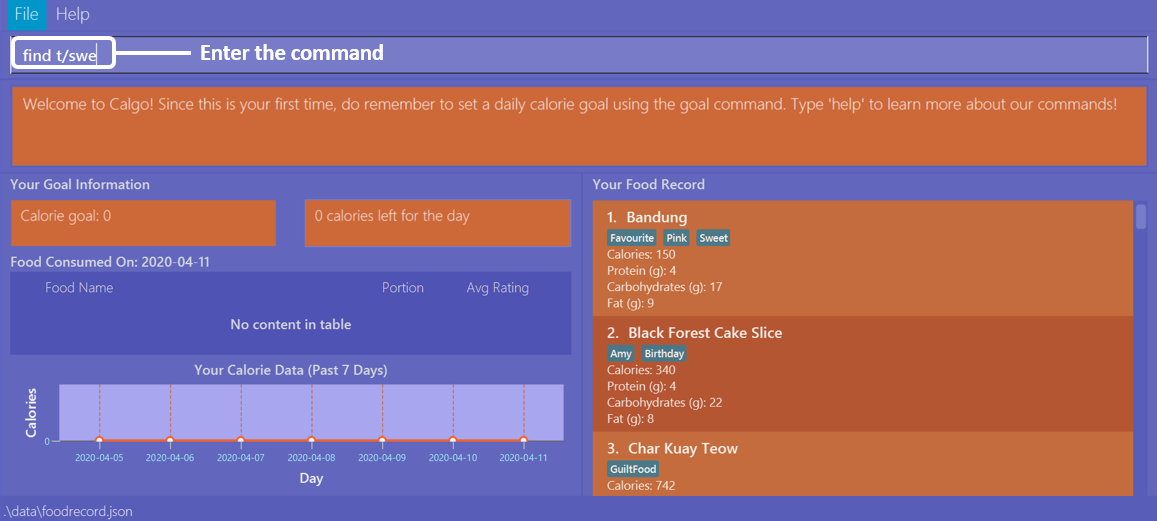
You can type find t/swe as input, and then press enter.
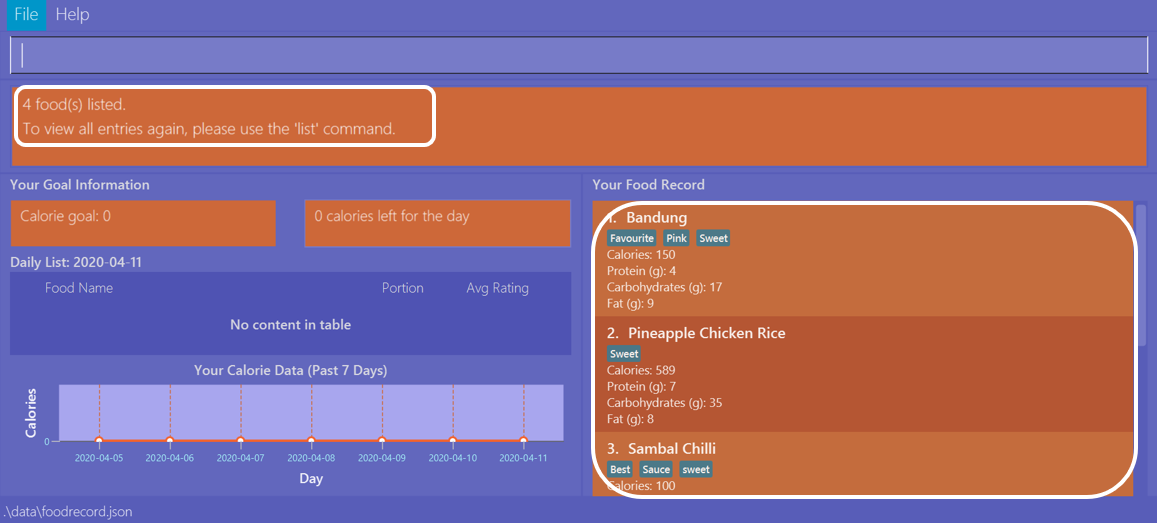
Upon entering the command, the Food Record will display all entries which have the swe keyword present in any one of
their tags. As you can search using incomplete keywords, the intended search for the sweet tag will also have its result shown.
Please note that the search is case-insensitive, an example being the resulting Sweet tag of Bandung. Moreover,
as with Example 2, we allow for incomplete words to be used as search keywords.
export : Exporting the current Food Record into a reference sheet
(by Eugene)
Obtaining a portable copy of the current Food Record may be useful for various purposes. For instance, you can
conveniently share your Food entries with friends, print the Food Record for future reference, or even adapt it to
suit your personal cooking needs in the kitchen. Whatever the purpose, we have you covered with the export command.
The export command provides you with a neatly formatted, editable file that reflects all entries in the current Food Record.
This file (named FoodRecord.txt) will be created in the data/exports folder.
Here are some key pointers for using the command:
This lets you manually track your diet using a reference sheet of your past Food entries. You can freely edit this
reference sheet to include information outside of Calgo. |
Certain Food names may be too long to fit into the given space. Such names will be shown on multiple lines.
However, rest assured that all your information is still captured and neatly organised.
Individual entries will also appear on separate lines.
|
Format: export
(any parameters entered are ignored)
Example:
Let’s suppose you wish to export the current Food Record so that you can print a copy for reference while cooking. Here’s how you can do it:
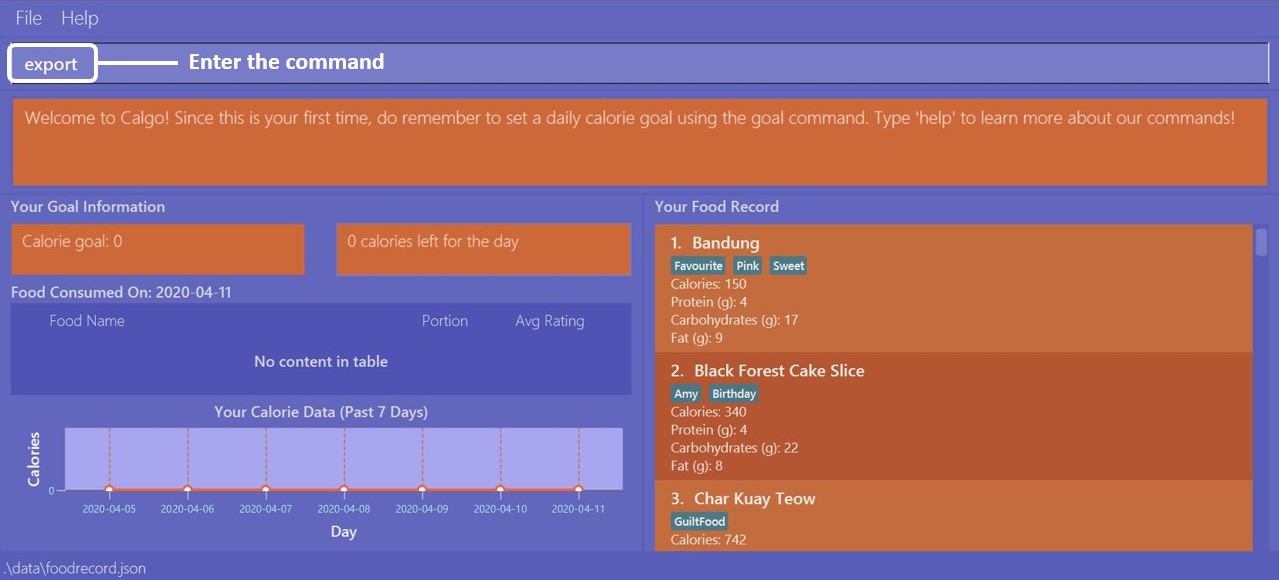
You should type in the command and press enter, as seen above.
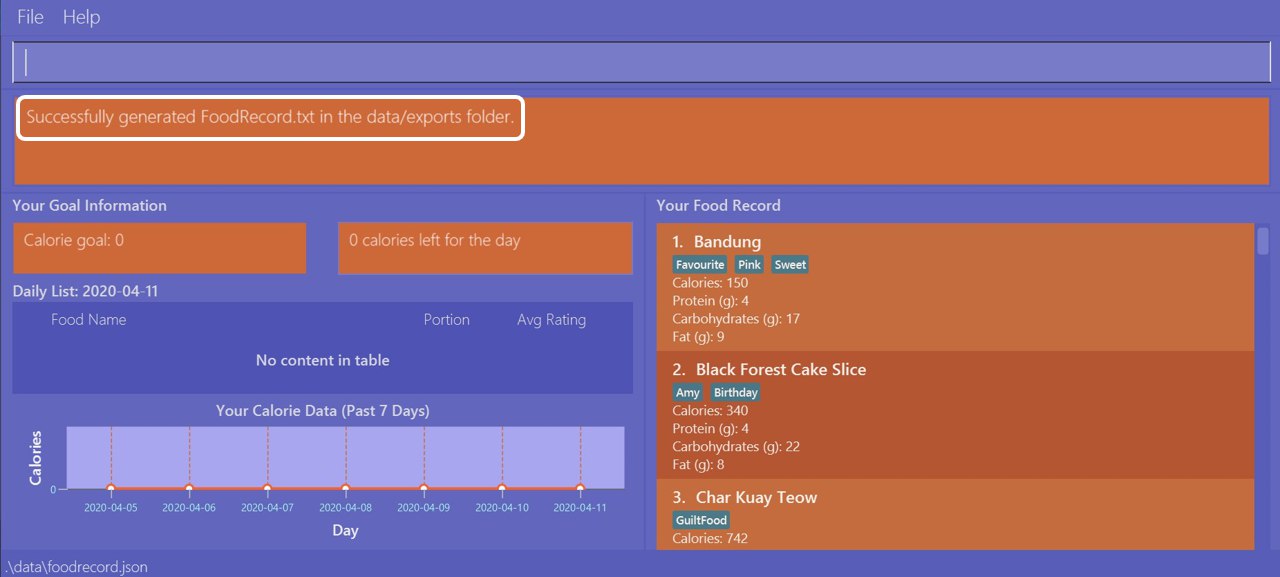
Doing so, Calgo will show you a result message indicating the copy has been successfully generated.
You can find this copy (named FoodRecord.txt) in the data/exports folder.
list : Listing all Food in current Food Record
(by Eugene)
With a large number of entries in the Food Record, you may remember that we can use the find
command to display only the relevant Food entries. Once we are done with the search, we will eventually want to
view all entries again. This is where the list command comes in handy.
The list command resets the display accordingly to show all entries in the Food Record. These entries will be neatly sorted,
just as the Food Record previously appeared:
You can think of this as the reverse of a find command.
After a find command, you are advised to complete your intended actions first, before using the list command to
reset the display. This allows for a smoother workflow as you will now avoid the need to perform the same find command again.
|
Format: list
(any parameters entered are ignored)
Example:
Let’s say you want to view all entries again after performing a find n/Chicken command. You can do the following:
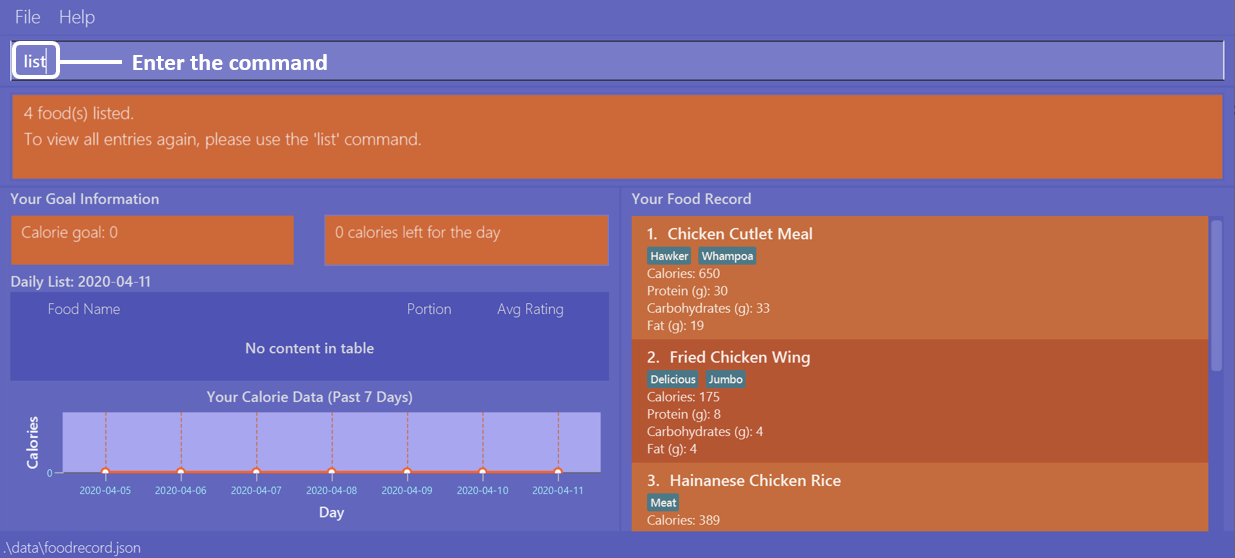
Type list as input, then press enter.
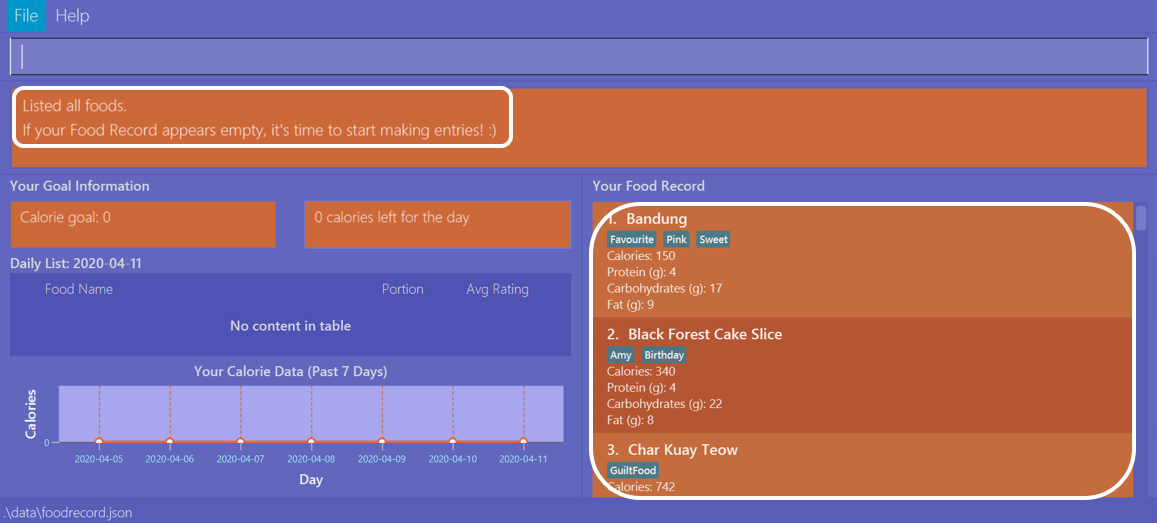
The Result Display will then indicate the result of your command, and the Food Record will now show all Food entries once again.
Contributions to the Developer Guide
Given below are sections I contributed to the Developer Guide. They showcase my ability to write technical documentation and the technical depth of my contributions to the project. Please note that some hyperlinks may not work as the guide is not part of this portfolio. |
Storage component
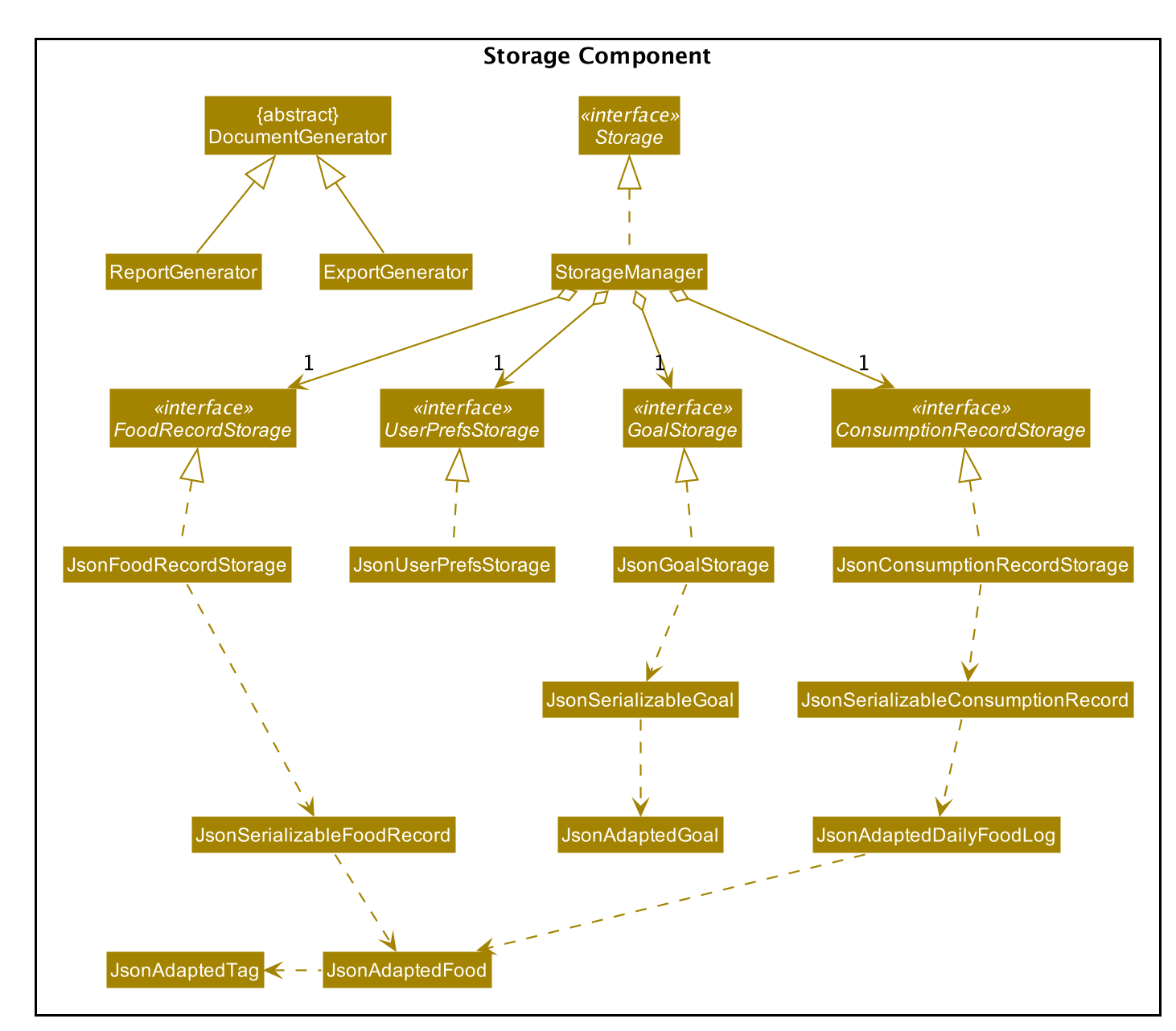
API : Storage.java
The Storage component allows us to save FoodRecord, UserPref, Goal, and ConsumptionRecord data in json format onto the disk, and read them back later on during the next session.
This would facilitate the following functions:
-
Load past user App data and preferences.
-
Generate and save insights reports based on previously and currently recorded user consumption.
-
Generate and save a user-friendly version of the accumulated
FoodRecord.
Searching for specific Food via categories and substrings
(by Eugene)
This section addresses how the find and list commands work. As they are complementary in their functions during the search process, both find and list commands will be explained together here for better coherence.
The find command allows us to search through the FoodRecord (via categorical or substring search) based on what the user enters for the Prefix. Users may enter one and only one Prefix. The search results can then be displayed in the GUI’s Food Record.
Meanwhile, the list command allows us to reset the GUI’s Food Record to once again show all entries in lexicographical order. This can be thought of as the reverse of a find command. However, unlike the find command, the list command does not use any Prefix, and ignores any input after its command word.
Prefix here indicates which Food attribute we are interested in. Categorical search finds Food objects with values that match the user-specified value representing one of the nutritional categories (Calorie, Protein, Carbohydrate, or Fat). Meanwhile, substring search finds matches for the user-entered substring in any part of the the Name or in any of the Tag objects belonging to the Food objects.
|
| For more information on lexicographical ordering, please refer to its relevant section here. |
The above commands rely on the FindCommand and ListCommand objects respectively. Objects of both classes use a Predicate<Food> object to filter through the current Food objects, where Food objects will be displayed in the GUI’s Food Record should they evaluate these predicates to be true.
Implementation
To search via a particular Food attribute, we use a FindCommandParser to create the corresponding Predicate<Food> based on which Food attribute the Prefix entered represents. This predicate is then used to construct a new FindCommand object, which changes the GUI display when executed.
The class diagram below shows the relevant Predicate<Food> classes used in the construction of FindCommand objects.

FindCommand objectsAs seen in the above class diagram, each Predicate<Food> is indeed representative of either Name, Calorie, Protein, Carbohydrate, Fat, or Tag. Moreover, it should be noted that each of these predicates test against a Food object, and therefore have a dependency on Food.
The sequence diagram below demonstrates how the find command works, for both categorical and substring search:
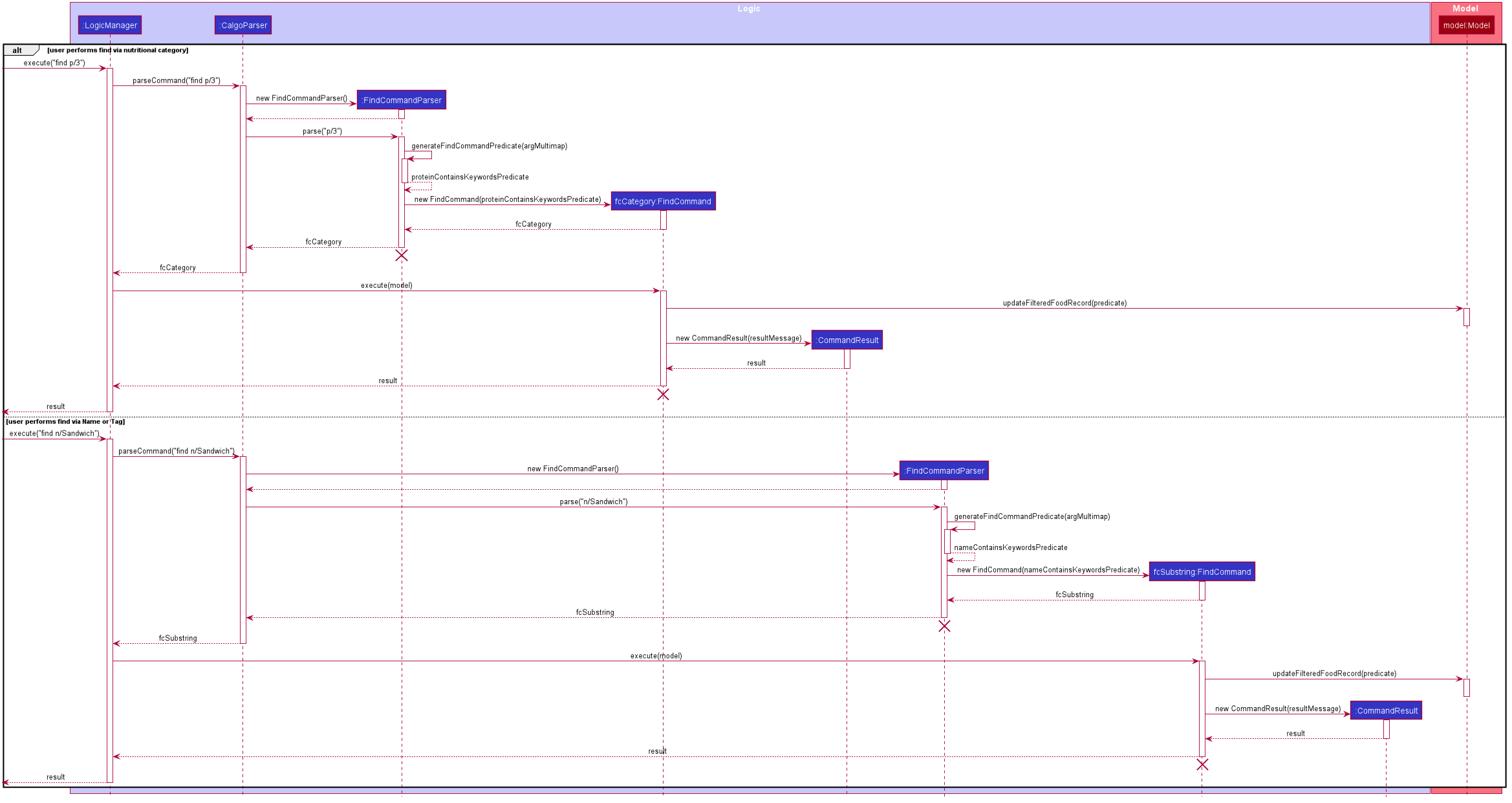
find command: Categorical Search and Substring Search
The lifeline for the both of the FindCommandParser objects, and both of the FindCommand objects should end at their destroy markers (X) but due to a limitation of PlantUML, the lifelines reach the end of diagram.
|
From the above, it is clear that both categorical search and substring search of the find command have similar steps:
Step 1: LogicManager executes the user input, using CalgoParser to realise this is a find command, and a new FindCommandParser object is then created.
Step 2: The FindCommandParser object parses the user-entered arguments that come with the Prefix, creating a Predicate<Food> object based on which Food attribute the Prefix represents.
-
In the above diagram examples, a
ProteinContainsKeywordsPredicateobject is created for the categorical search viaProteinwhile aNameContainsKeywordsPredicateobject is created for the substring search viaName.
Step 3: This Predicate<Food> object is then used to construct a new FindCommand object, returned to LogicManager.
Step 4: LogicManager calls the execute method of the FindCommand created, which filters for Food objects that evaluate the predicate previously created to be true. It then returns a new CommandResult object reflecting the status of the execution. These changes are eventually reflected in the GUI.
The find command therefore searches through the existing FoodRecord and then displays the relevant search results in the GUI’s Food Record. To once again show all Food entries in the display, we use the list command.
In constrast to FindCommand, the ListCommand constructor takes in no arguments and simply uses the predicate Model.PREDICATE_SHOW_ALL_FOODS to always show all Food entries in its execute method. This is described by the sequence diagram below:
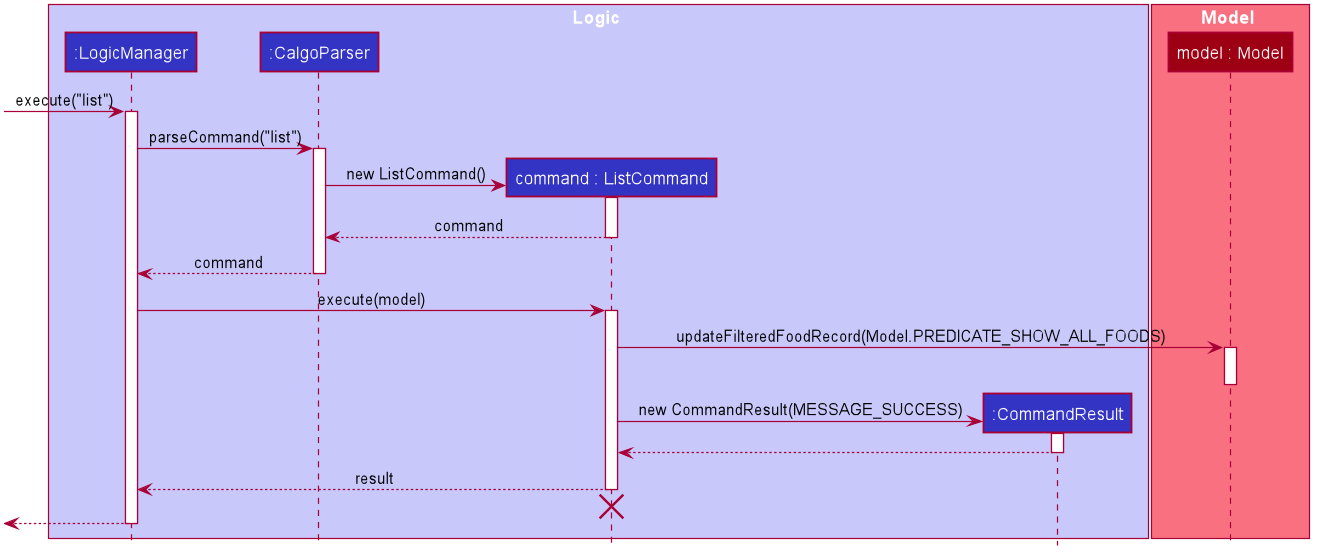
list command
The lifeline for the ListCommand object should end at the destroy marker (X) but due to a limitation of PlantUML, the lifeline reaches the end of diagram.
|
How the list command works:
Step 1: LogicManager executes the user input, using CalgoParser to realise this is a list command, and a new ListCommand object is created.
Step 2: LogicManager then calls the execute method of this ListCommand, which uses Model.PREDICATE_SHOW_ALL_FOODS to evaluate to true for all Food objects in the FoodRecord.
Step 3: LogicManager then returns a new CommandResult object to reflect the status of the execution, in the GUI. The GUI’s Food Record reflects the above changes to show all Food entries once again.
Design considerations
Aspect: Predicate construction source.
-
Alternative 1 (current choice): Each
Predicate<Food>is constructed using a new object of type eitherName,Calorie,Protein,Carbohydrate,Fat,Tag.-
Pros:
-
Defensive programming by building new objects rather than relying on mutable sources.
-
Can reuse existing code and classes like ArgumentMultimap and their methods.
-
Models objects well to reflect the real-world.
-
-
Cons:
-
May be more resource-intensive than other alternatives.
-
New developers may not find this intuitive.
-
-
-
Alternative 2: Each
Predicate<Food>is created using aStringwhich represents the keywords.-
Pros:
-
Easier to implement with fewer existing dependencies.
-
Less resource-intensive.
-
-
Cons:
-
More prone to bugs.
-
Difficult to ascertain which
Foodattribute it actually represents. -
More difficult to debug as
Stringtype is easily modified. -
Does not reflect good OOP practices
-
-
Aspect: Enabling substring search.
-
Alternative 1 (current choice): Allow substring search for both
NameandTag-
Pros:
-
Improves user experience.
-
Can reuse common code as the approach for both
NameandTagare similar. -
Generally easy to implement substring finding.
-
Can use regular expressions if needed, which are powerful and suitable for our purpose.
-
-
Cons:
-
Requires good understanding of the original project.
-
Need to know the
Stringtype, regular expressions, and their implications. -
Need to implement searching via multiple types of
Foodattributes and hence introduces more dependencies. -
Need to implement a new
Parserclass to detect each relevantPrefix.
-
-
-
Alternative 2: Only allow exact word matches for
NameandTag-
Pros:
-
Can simply reuse large parts of the original project’s existing code.
-
Less prone to bugs.
-
Easy for new Computer Science student undergraduates to understand, who are likely to be the new incoming developers of our project.
-
-
Cons:
-
Diminishes user experience.
-
May not fully satisfy the user requirements.
-
Need to implement searching via multiple types of
Foodattributes and hence introduces more dependencies. -
Need to implement a new
Parserclass to detect each relevantPrefix.
-
-
Summary
In essence, this section focuses on searching which is implemented via find and list commands.
The find command performs a categorical search if a value from a nutritional category (Calorie, Protein, Carbohydrate, Fat) is specified. Otherwise, a substring search is performed to find Food objects that contain the entered substring in their Name or in one of their Tag s. These rely on the Predicate<Food> object used in constructing the FindCommand, which depend on the Prefix entered by the user.
Meanwhile, the list command simply uses the predicate already defined in Model to display all Food objects.
The above can be summarised in the activity diagram below:
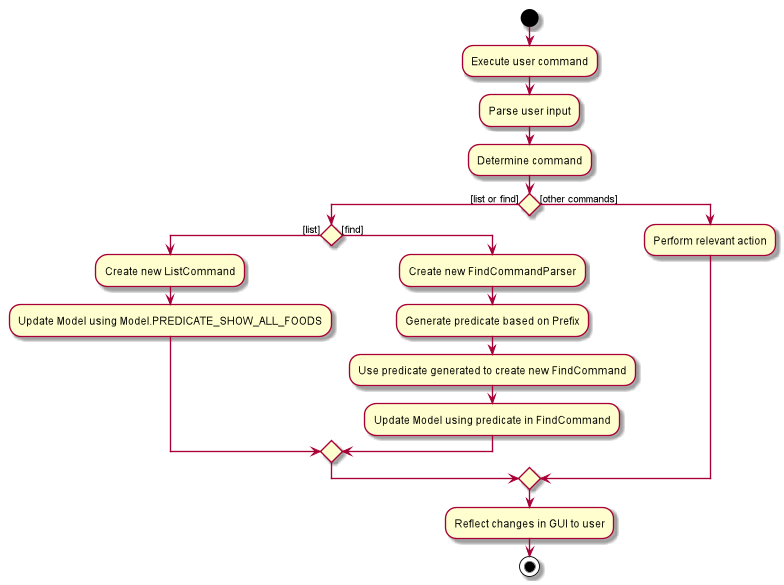
Lexicographical Food order
(by Eugene)
This section addresses how the GUI Food Record entries appear in lexicographical order, which is an effect of sorting Food objects in the FoodRecord.
Over time, users will eventually have many Food entries — these should be sorted for a better experience. Intuitively, the lexicographical order is the most suitable here.
In essence, Food objects are sorted by the UniqueFoodList (which is inside FoodRecord).
Sorting is performed each time Food object(s) are newly added to the UniqueFoodList, or during the initialisation of the UniqueFoodList upon App start-up.
There is no need to re-sort when a Food object is deleted or edited as the order is maintained.
For a better understanding of adding and editing Food objects using the update command, please refer to its relevant section here.
|
Although the the list command changes the GUI Food Record display, it does not actually perform sorting. It simply resets the GUI Food Record to show all Food entries, and is usually used after a find command. You can read more about them here.
|
Implementation
The UniqueFoodList is able to sort Food objects because the Food class implements the Comparable<Food> interface.
This allows us to specify the lexicographical order for sorting Food objects via their Name, using the following compareTo method in the Food class:
public int compareTo(Food other) {
String currentName = this.getName().toString();
String otherName = other.getName().toString();
return currentName.compareTo(otherName);
}How the sorting process works:
-
When the App starts up, a new
UniqueFoodListis created from the source json file (if available) or otherwise the default entries, and the createdFoodobjects are sorted as they are added to it. -
Existing
Foodobjects are therefore arranged in lexicographic order byName. -
Thereafter,
UniqueFoodListsorts theFoodobjects whenever newFoodobjects are added.
It should be noted that sorting is only performed by the addFood and setFoods method of the UniqueFoodList, which calls the sortInternalList method. Not to be confused, the setFood method, which is used when a Food object is edited, does not perform any sorting.
The sequence diagram below shows how the lexicographical ordering is performed when Calgo starts up:
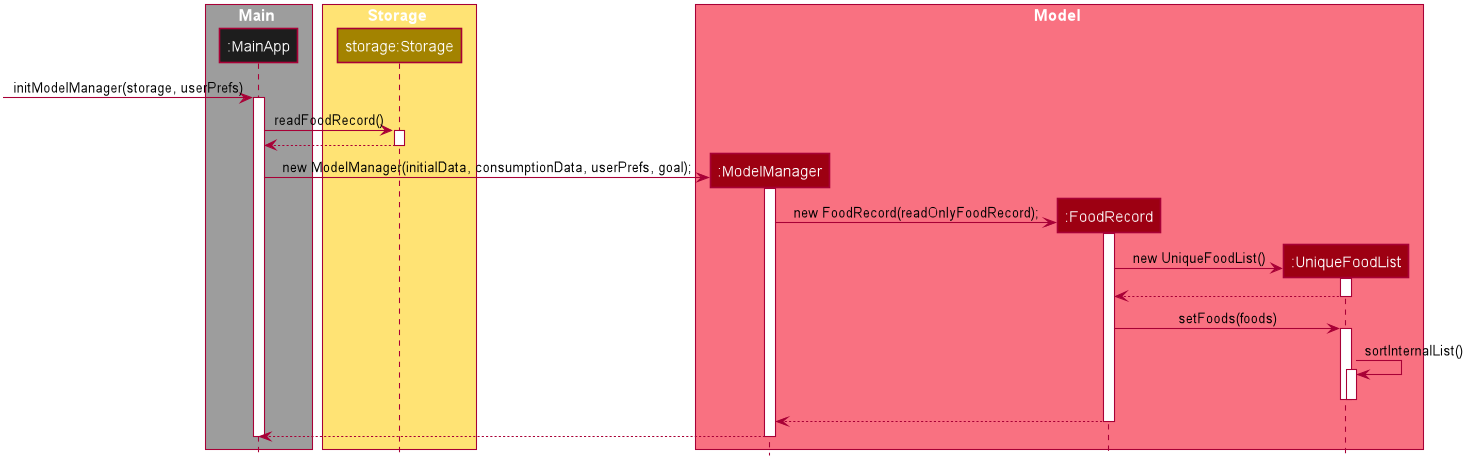
Based on the above diagram, when Calgo starts:
Step 1: We initialise the ModelManager object. For this, we use previously stored user data if available (by reading in from the source json files). Otherwise, we use the default Calgo Food entries.
Step 2: Before we can finish constructing a new ModelManager object, we require the creation of a new FoodRecord object which in turn requires the creation of a new UniqueFoodList object.
Step 3: Once UniqueFoodList is constructed, we introduce the initialising data into it using the setFoods method. This calls the sortInternalList method, which sorts the newly added Food objects in the ObservableList<Food> contained in UniqueFoodList, according to the specified lexicographical order (defined in the Food class).
Moving on, the sequence diagram below (which is a reference frame omitting irrelevant update command details) describes the lexicographical sorting process when Food objects are added (not edited) using the update command:
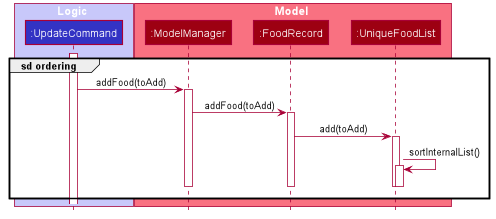
This is in a reference frame as it is reused in the update section here)
|
Here, the diagram describes what happens after parsing the user input and creating an UpdateCommand object. Since the Food entered by the user is an entirely new Food object without a Name-equivalent Food existing in the UniqueFoodList:
Step 1: We call the respective addFood and add methods as seen in the diagram, eventually adding the Food object into the UniqueFoodList and arriving at its sortInternalList method call.
Step 2: The sortInternalList method then sorts the Food objects in the ObservableList<Food> contained in UniqueFoodList, according to the specified lexicographical order defined in the Food class.
During an update command, we do not perform sorting if the user enters a Food object that already has an existing counterpart with an equivalent Name in the UniqueFoodList.
|
Any re-ordering will eventually be reflected in the GUI, facilitated by the following (in the case of an update command) or otherwise something similar:
model.updateFilteredFoodRecord(Model.PREDICATE_SHOW_ALL_FOODS);Design considerations
Aspect: Frequency of sorting operation.
-
Alternative 1 (current choice): Sort whenever a new
Foodis added or during App start-up.-
Pros:
-
Guarantees correctness of sorting.
-
Saves on computational cost by not sorting during deletion or edits as the order is preserved.
-
Computational cost is not too expensive since the introduced
Foodobjects usually come individually rather than as a collection (except during App start-up).
-
-
Cons:
-
Need to ensure implementations of various commands changing the
Modelare correct and do not interfere with the sorting process. -
May be computationally expensive if there are many unsorted
Foodobjects at once, which is possible when Calgo starts up.
-
-
-
Alternative 2: Sort only when calling the
listcommand.-
Pros:
-
Easier to implement with fewer existing dependencies.
-
Uses less computational resources since sorting is only done when
listcommand is called.
-
-
Cons:
-
Diminishes user experience.
-
May be incompatible with certain
Storagefunctions. -
May lead to bugs in overall product due to incompatible features.
-
-
Aspect: Data structure to store Food objects.
-
Alternative 1 (current choice): Use
UniqueFoodListto store allFoodobjects.-
Pros:
-
Can reuse existing code, removing the need to maintain a separate list-like data structure.
-
Based on existing code, any changes to the
Modelfrom the sorting process are automatically reflected in the GUI. This is very useful for testing and debugging manually.
-
-
Cons:
-
Many of the underlying
ObservableListmethods are built-in and cannot be edited. They are also difficult to understand for those unfamiliar. This can make development slightly trickier, especially in following certain software engineering principles.
-
-
-
Alternative 2: Use a simpler data structure like an
ArrayList.-
Pros:
-
Easy for new Computer Science student undergraduates to understand, who are likely to be the new incoming developers of our project.
-
-
Cons:
-
More troublesome as we require self-defined methods, abstracted over the existing ones. If not careful, these self-defined methods can possibly contain violations of certain software engineering principles, which may introduce regression in the future.
-
May be inefficient in using resources.
-
-
Summary
The UniqueFoodList facilitates the lexicographical ordering of Food objects and hence how their respective entries appear in the GUI Food Record. This can be summarised in the activity diagram below:
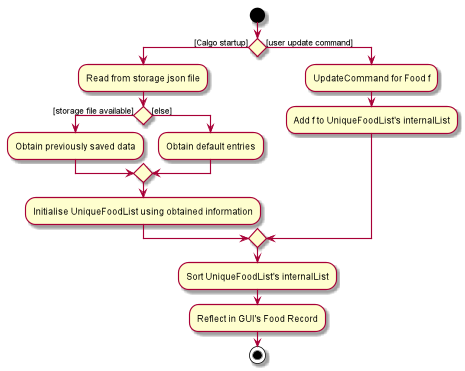
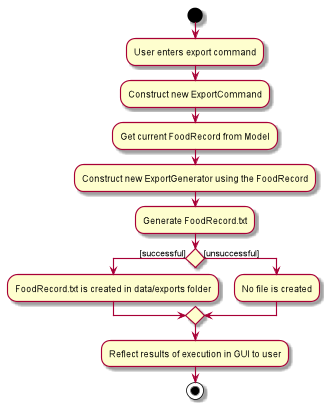
Exporting the current FoodRecord into a portable file
(by Eugene)
This section addresses how the export command works, creating a FoodRecord.txt file showing details of all the Food objects currently stored in the FoodRecord. The information is presently neatly in table form and the file is created in the data/exports folder.
The export command mainly uses an ExportGenerator object to generate the file. All formatting options and methods to write the contents of the file are included in the ExportGenerator class, which extends the DocumentGenerator class.
You may find the report command similar as they both create a new file for the user. You can read more about it here.
|
Implementation
Most of the work in generating the file is done by the generateExport method of ExportGenerator. You can access the class to view its methods for writing the header and footer components, which are relatively easily to understand.
However, the methods for writing the file body is likely where some explaining is required. Here, the formatting of the table body is determined by the following:
private static final int NAME_COLUMN_SIZE = 45;
private static final int VALUE_COLUMN_SIZE = 20;NAME_COLUMN_SIZE represents the allowed space for the Name. If a Food object has a Name which is too long, the Name will be truncated and continued on the following lines.
Meanwhile, VALUE_COLUMN_SIZE represents the allowed space for each nutritional value of Calorie, Protein, Carbohydrate, and Fat in the table. These are guaranteed to be within a length of 5 characters when parsing, and should not exceed the given space.
The nutritional values will always be shown in the first line of their respective Food object after its (possibly truncated) Name. This is facilitated by the printBody method of ExportGenerator, which calls its printBodyComponent method and subsequently its generateFinalisedEntryString method, which performs the truncation and amendment of the Name as necessary.
Moving on, the sequence diagram below demonstrates how the export command works to create the user copy of the current FoodRecord:
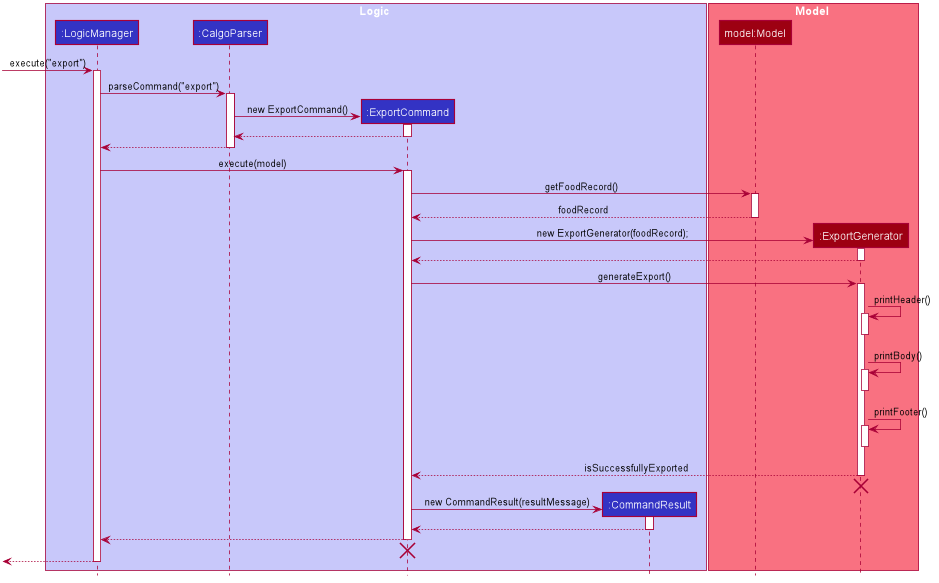
export command: Generating FoodRecord.txt
The lifeline for the ExportCommand object and that of the ExportGenerator object should end at their destroy markers (X) but due to a limitation of PlantUML, the lifelines reach the end of diagram.
|
From the above, creating FoodRecord.txt involves the following steps:
Step 1: LogicManager executes the user input, using CalgoParser to realise this is a export command, and a new ExportCommand object is created.
Step 2: LogicManager then calls the execute method of this ExportCommand object. This results in a call to the Model to get the current FoodRecord, which is used to construct a new ExportGenerator object. The ExportGenerator is responsible for creating the FoodRecord.txt file and writing to it.
Step 3: ExportCommand then calls the generateExport method of ExportGenerator, writing the required parts to the file. This returns a boolean indicating whether the file creation and writing are successful.
Step 4: A new CommandResult object indicating the result of the execution is then constructed and reflected in the GUI.
Design considerations
Aspect: Type of file to create.
-
Alternative 1 (current choice): Create a .txt file to represent the
FoodRecord.-
Pros:
-
Satisfies user requirements by allowing editing of the file to include custom entries.
-
-
Cons:
-
Need to define new classes and methods for file writing, which may introduce more dependencies.
-
May be more resource-intensive than other alternatives.
-
New developers may be unfamiliar with
Stringmanipulation and regular expressions.
-
-
-
Alternative 2: Create a .pdf file to represent the
FoodRecord-
Pros:
-
The contents appear to be more legitimate.
-
Can use external libraries for convenience.
-
May be less resource-intensive.
-
-
Cons:
-
May not satisfy user requirements as the file cannot be edited easily.
-
May introduce more bugs, additional dependencies, and become prone to external factors.
-
More difficult to debug due to lack of familiarity with external libraries.
-
May require more space.
-
-
Aspect: Abstraction for ExportGenerator and ReportGenerator.
-
Alternative 1 (current choice): Create
DocumentGeneratorabstract class which bothExportGeneratorandReportGeneratorextends.-
Pros:
-
Good OOP practice, following its principles.
-
Allows for code reuse and neater code.
-
Able to apply concepts of polymorphism, if required.
-
May be now easier to debug.
-
-
Cons:
-
Need to define new class, possibly introducing more dependencies.
-
Need to identify what is common to both
ExportGeneratorandReportGenerator.
-
-
-
Alternative 2: Use an interface which both classes will implement.
-
Pros:
-
Similar to Alternative 1.
-
-
Cons:
-
Does not allow methods to be defined in the interface. (Some exceptions: default methods, etc)
-
May need to repeat definitions which may be the same for both classes.
-
-
-
Alternative 3: Do not use an interface or abstract class.
-
Pros:
-
Requires less effort.
-
Does not introduce additional dependencies.
-
-
Cons:
-
Unable to reap benefits of the above alternatives.
-
-
Summary
In short, this section addresses how users are able to obtain an editable copy of the current FoodRecord using the export command.
The export command largely relies on the ExportGenerator class, which facilitates creating the file and writing to it.
The above can be summarised in the activity diagram below: